From Research to Product: Customer Insights on Prompt flow
Time to navigate the frontier
In the dynamic landscape of Large Language Models (LLM), our team is once again at the cutting edge, pioneering a new venture called Prompt flow (PF). My role transcends the rapid and high-quality delivery of products. I need to contemplate the features that can deliver real values to our customers and the user experience that resonates with the essence of those features. This new challenge is substantial for a web front-end engineer and has been a focal point of my professional contemplation.
As 2023 drew to a close, a fortuitous invitation from a university peer led me to explore the synergy between LLMs and conventional ML models. This exploration transformed me into an amateur researcher, granting me the privilege to scrutinize the research process through our customers’ lens, with the aim of pinpointing their pain points to better inform our product design.
Recent academic work I learned from
This paper has been accepted by ACL 2024 Findings few days ago, a great encouragement for us. Please read the full paper if you’re interested in details, which will not be interpreted here.
Harnessing LLMs as post-hoc correctors
A fixed LLM is leveraged to propose corrections to an arbitrary ML model’s predictions without additional training or the need for additional datasets.
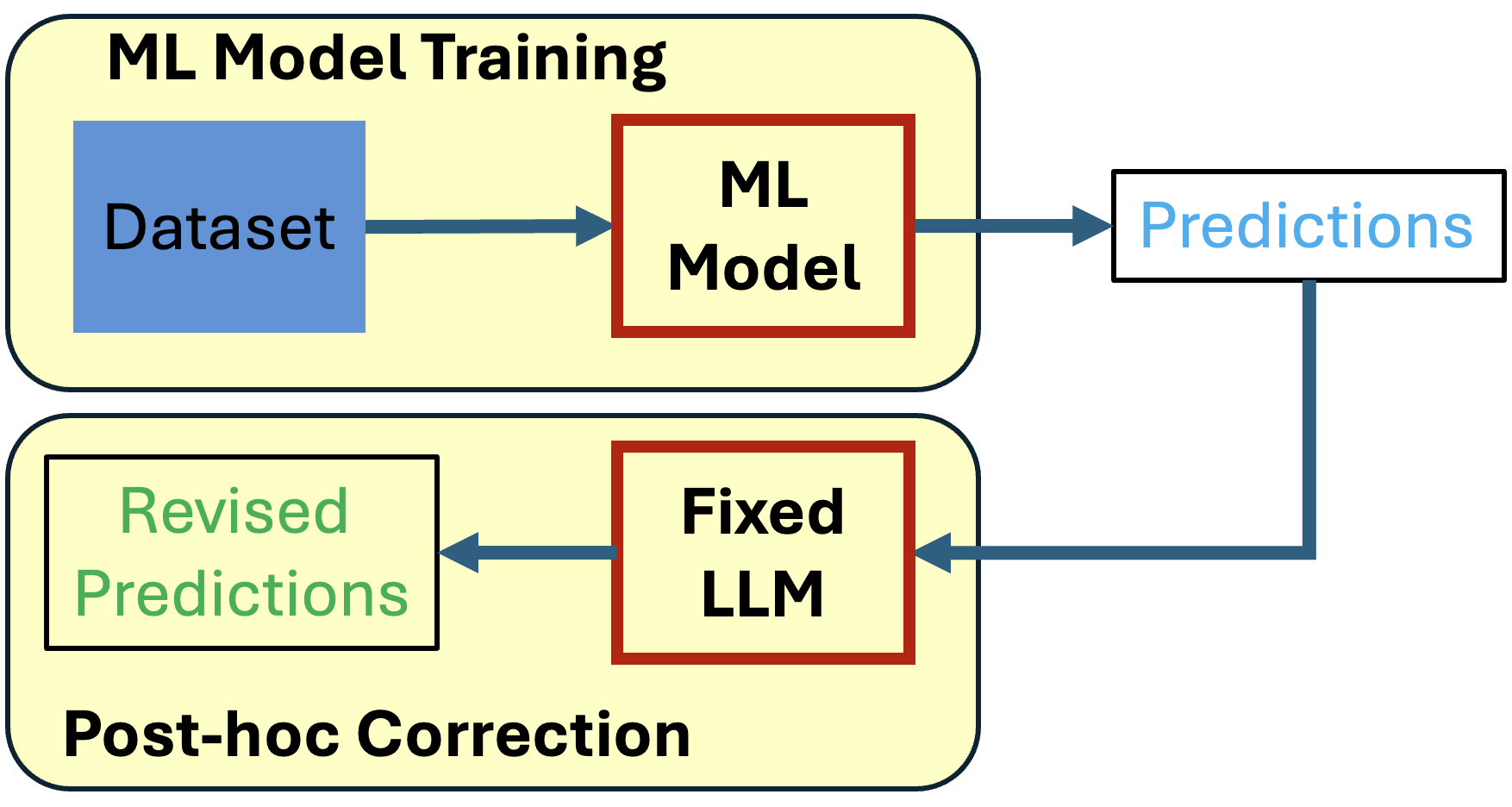
A high-level overview of LLMCORR
Harnessing Large Language Models (LLMs) as post-hoc correctors to refine predictions made by an arbitrary Machine Learning (ML) model.
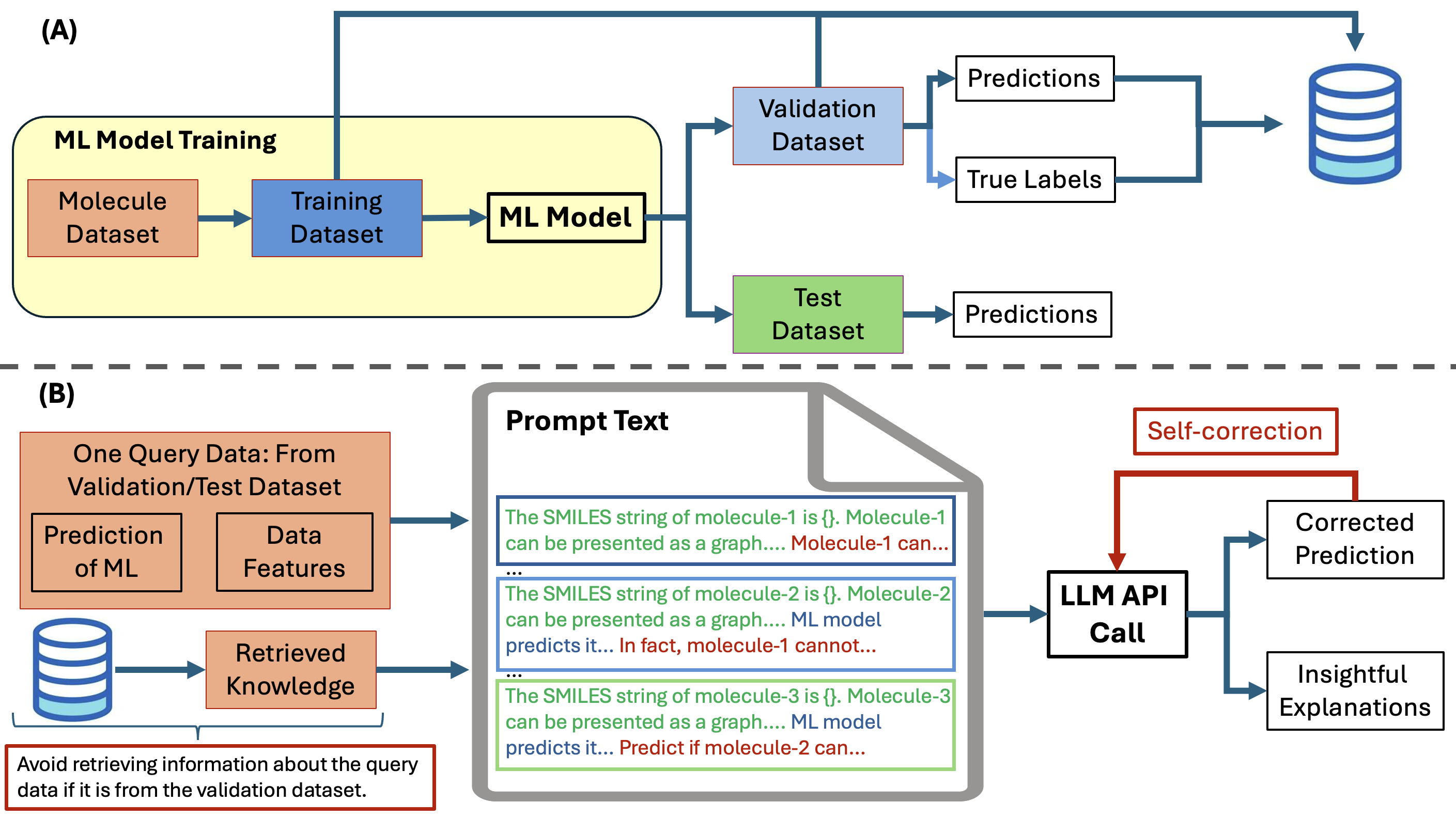
LLMCORR prompt template
Multiple contextual knowledge from training and validation datasets can be included by expanding the template.

Reflections on Prompt flow
I have been deeply involved in PF since the inception of this project. Naturally, I endeavored to integrate it into our research, yet reality diverged from my original intentions. Hence, let’s see these few reflections on PF throughout the research journey. Please note that most of our works were done before early February of 2024, so I don’t mean to be a monday morning quarterback for some points.
1. Support and optimization of local inference experience will gain more customer favor
Most researchers and engineers have certain computational resources, and from the perspective of cost control, they are likely to choose open-source large language models (LLMs) for local inference work, which PF does not support. We have similar story that opted for LLMs like Llama at the beginning of the experiment, which meant giving up on PF.
2. Flex mode is crucial for the use of flow
Despite transitioning to OpenAI’s GPT3.5/4 models, our repository was already rich with Python utilities and Jupyter notebooks, complemented by a wealth of projects from previous research endeavors. The core competitive edge of PF aside, the availability of flex mode at that juncture would have allowed for an exploratory integration with our established GNN workflow, potentially igniting a synergistic spark.
3. Is Prompt engineering really that important?
The value of our work lies in placing LLM to an interesting position with right work in the system to maximize its value. The prompts designed and used are relatively common today: simple structure, essential knowledge and few-shots. Therefore prompt engineering have not played the key role in this work.
It is worth mentioning that PF recently launched the Prompty feature, which provides quick access and focuses on the value of tuning prompts. This may be practical in large engineering applications, where the content of a single prompt can range from hundreds to thousands of lines. If the scenario holds, then support complex Jinja Template Designer features and preview the final prompt content will be of great help (just like Overleaf does).
4. What PF did right?
When we began to learn and try to implement RAG App, we naturally looked at some LangChain samples first, then… went from beginner to giving up. My teammate chose the OpenAI Playground to use the GPT4 Assistants feature, meanwhile Azure OpenAI had not supported Assistants yet, so I chose to build a RAG flow following the PF sample. In this scenario, there are a few advantages to note:
- Low-code is always easy to build PoC.
- Orchestration to do batch run.
- Tracing (Not implemented yet at that time, but definitely a keeper feature).
Of course, there are also points worth discussing, such as whether you still need to write some code that will affect the ease of use assessment if it is not clear in the sample that embeddings are generated using the same model set and stored in the vector database; or the data input and output in the batch run scenario, which also involves a lot of manual work.
Another aside, the performance of File retrieval of OpenAI (OAI) Assistants was not satisfactory at that time. I wonder if there has been a significant improvement after it was renamed to File Search now.
5. What should PF focus on if it conducts Experiments?
Firstly, there are some old topics, such as experiment status display and refresh, CRUD operations and viewing logs at each step, which are essential features of various products.
When the amount of experimental data is huge, limitations on metrics like RPM and TPM will start to trouble users. Thus, how to estimate the number of tokens and requests for experiments under these constraints by services like OAI and Azure OpenAI (AOAI) to achieve automated high-concurrency scheduling, and even support multi-endpoints concurrency, will be a great value to customer. In previous experiments, we implemented very basic token calculation and request interval logic, and I believe we are not the only ones with such needs.
Last few words
It’s not commonly encouraged for engineers to delve into academic pursuits, since not everyone possesses the passion, foundation, or even time. However, in the era of Generative AI, immersing oneself in scholarly articles is always a wise move!
Whether in practical application or academic experimentation, only through in-depth engagement can one truly understand and unearth the pain points of users. I believe this embodies the spirit of our current discussion.